Case Study: Technical Debt at Stack Overflow
For several years I worked as a web developer at Stack Overflow. As with every company, Stack Overflow has some technical debt in its systems (remember, technical debt is inevitable), and this is a story about a particular piece of technical debt which I was involved with. This is an interesting example because it demonstrates how the changing requirements of a changing business lead to the creation of technical debt. It’s also a story with a happy ending, because I was able to successfully implement a plan for fixing it.
CareersAuth
In 2016, I was working on a redesign of the login experience for Stack Overflow Talent, which up until that time had been known as Stack Overflow Careers. This is the portal that employers use to post job listings, create company pages and search for candidates on Stack Overflow.
I was changing this crufty old login page, with its prominent OpenID options:
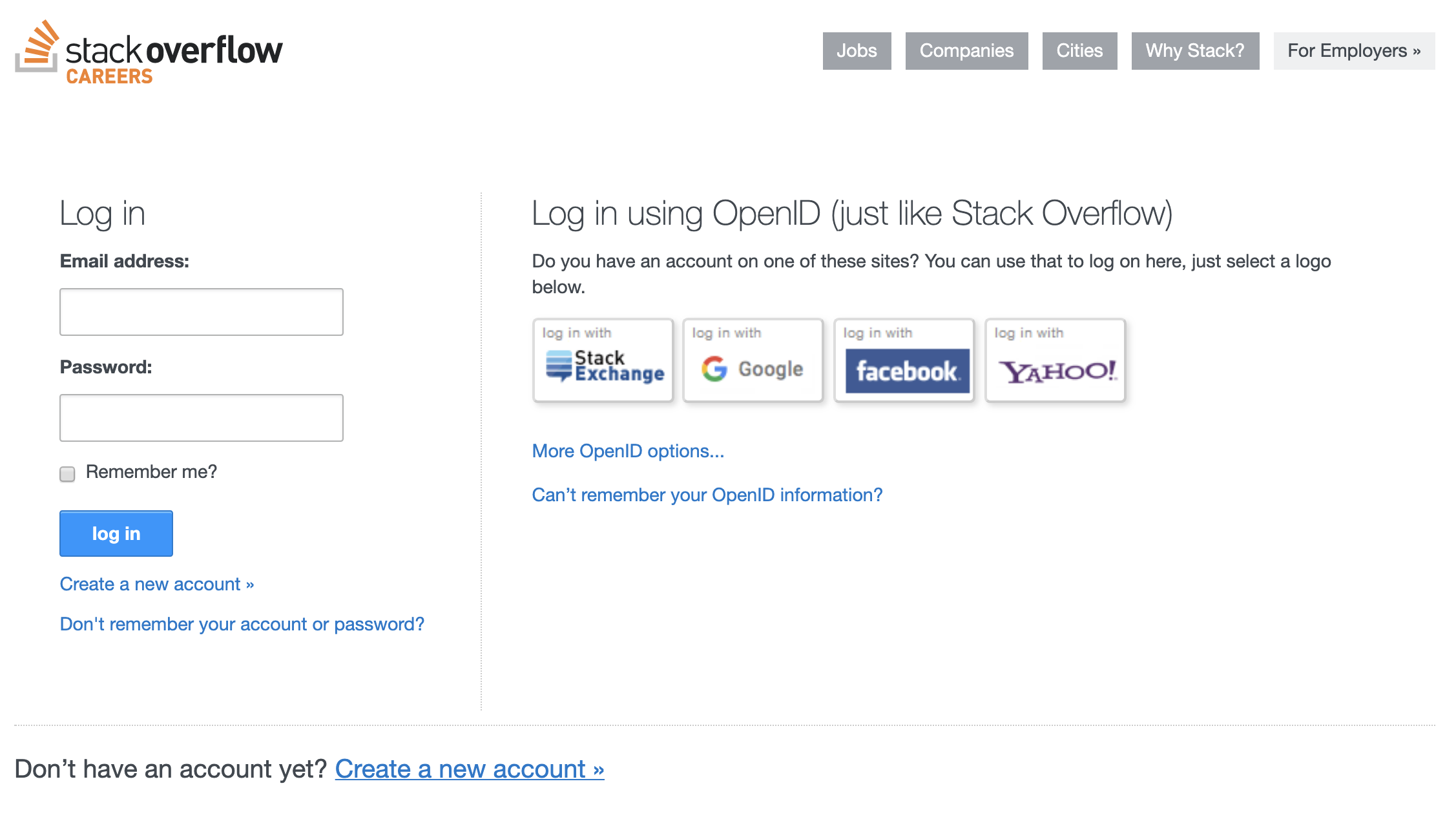
To something more like the one which had recently been implemented on the main Stack Overflow Q&A site:
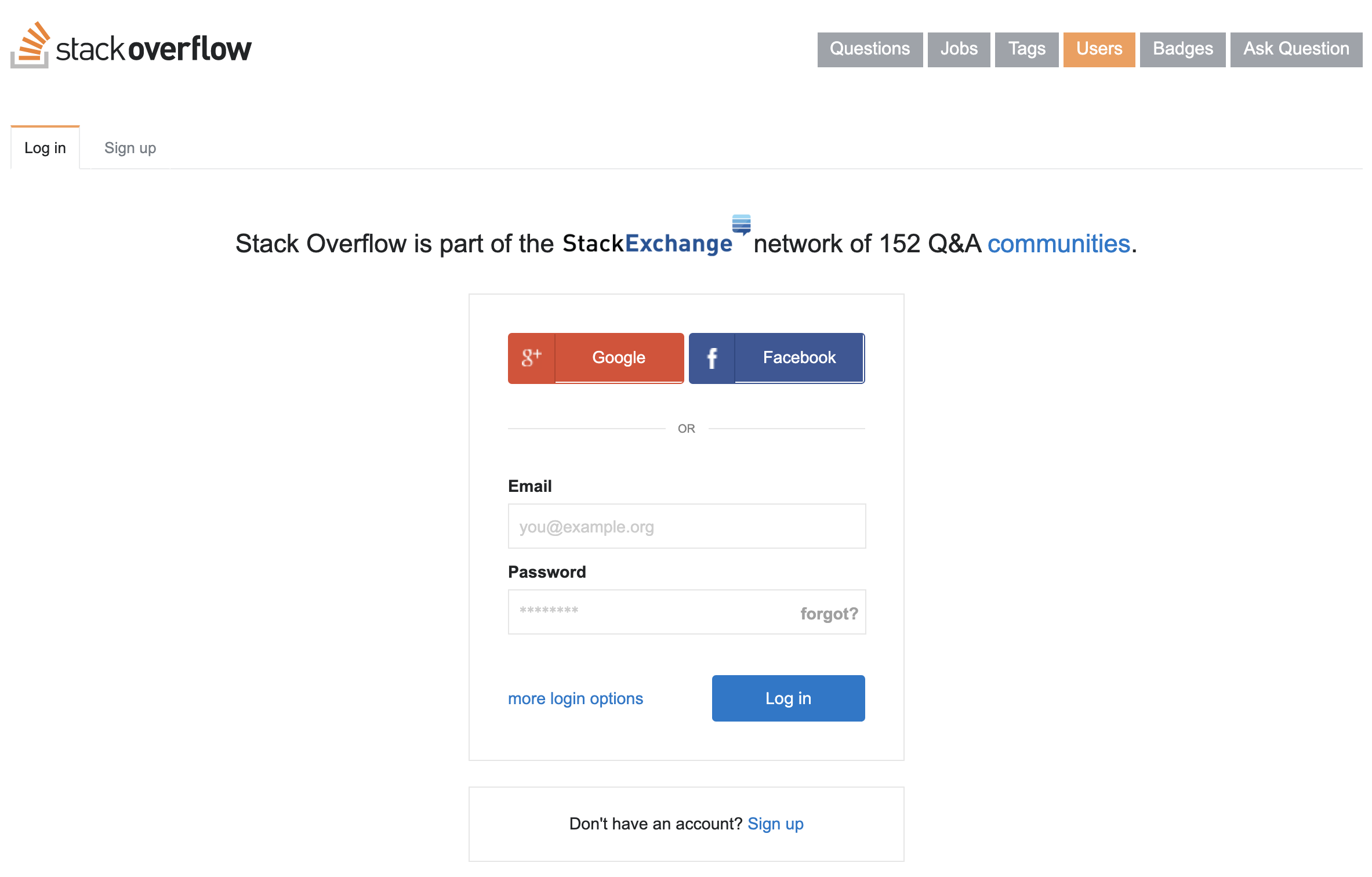
This looked like it should be simple - just a bit of HTML and CSS tweaking, pretty much copying and pasting from the Q&A codebase, right? Well, there was a little bit more to it than that. There wasn’t just the design of the form to consider, but its behaviour - things like user input validation, and where to display messages such as “incorrect password” notifications.
OK, but the behaviour of a login form is also pretty straightforward, isn’t it? Copy and paste some front-end JavaScript, and maybe some of the back-end code too? The Q&A codebase was C#, and the Talent codebase was also C#, so that should all be quick and easy.
Well, almost. Unlike the Q&A site, on the Talent site it turned out that the code for handling user login and registration was split across two different codebases. The UI lived in the main Stack Overflow Talent codebase, but there was a separate site called CareersAuth that received the login and registration form posts, and handled validating and storing usernames and passwords.
This slowed me down a bit while implementing the updated redesign. Firstly, CareersAuth hadn’t been touched for several years, so I had to spend some time updating various dependencies before I got it to work locally on my developer machine. Secondly, being on a separate site to the login and registration forms slowed me down with some of the UI changes I had to make.
There were other limitations of this architecture. There was no mechanism for users to change their passwords while they were logged in, which seemed like it should have been pretty basic functionality. Email addresses were stored in two places, as Talent had its own Users table, and CareersAuth had a separate database. That meant that when users changed their email address on Stack Overflow Talent, this was not reflected on the separate CareersAuth database - so if they forgot their password, they couldn’t get a password reset sent to their new email address.
It wouldn’t have been completely impossible to create solutions to these kinds of issues, but the code required would have been unnecessarily complex, and testing would have been unnecessarily difficult. The work would would have taken longer than seemed reasonable for the trickle of users that were affected, which meant that it was never a big priority. These were the kinds of issues that languished, requiring workarounds from the support team. Need to change your password? Just log out and hit the “forgot password” button, and then you can reset it to something else. Changed your email address and can’t get a password reset? Just get in touch with support, and we’ll go in and update the “other” database.
Why had intelligent people implemented this in such a strange way? It turns out that, as with a lot of technical debt, it was the result of a series of decisions, all of which made perfect sense at the time. Let’s look at a little history.
A failed bet on OpenID
When Stack Overflow launched in 2008, a technical decision was taken which co-founder Jeff Atwood wrote about at the time in a blog post called OpenID: Does The World Really Need Yet Another Username and Password?
As we continue to work on the code that will eventually become stackoverflow, we belatedly realized that we’d be contributing to the glut of username and passwords on the web. I have fifty online logins, and I can’t remember any of them! Adding that fifty-first set of stackoverflow.com credentials is unlikely to help matters. With some urging from my friend Jon Galloway, I decided to take a look at OpenID.
In those days, we still had this idea that the internet was comprised of lots of interoperable services, rather than things being centralised in the control of just a few enormous tech companies. OpenID pre-dated users being able to log in to websites with their Facebook or Google accounts. While Facebook or Google could implement OpenID themselves to give their users the ability to do that, anybody could be their own OpenID provider if they had their own website. Then they wouldn’t need to rely on a big company to give them one-click login to other websites all over the web.
So, Stack Overflow took a bet on OpenID being the future. It would save them the hassle of having to deal with passwords - no need to worry about storing them securely, and no support calls from people who have forgotten their password, because all of that stuff is effectively outsourced to whoever that user’s OpenID provider is. In the future, maybe every website would accept OpenID, and so users would be accustomed to logging in that way.
Unfortunately, that didn’t quite come to pass. While Google did indeed implement OpenID themselves, Facebook took a slightly different (and incompatible) approach, and while it is common these days to log into websites using your Facebook or Google account, we don’t use OpenID for that any more, and Stack Exchange’s own support for OpenID ended in 2018.
Instead, websites use a technology called OAuth. This isn’t interoperable in the same way that OpenID was - if a website only supports logins from, say, Google, you can’t use your Facebook account to log in. Users are limited to logging in using one of the big tech companies. On the plus side, it is a simpler system for users to understand, and pretty much everybody has a Google or Facebook account these days. With OpenID, you’d have to find your provider from a big list of options, or enter your unique OpenID URL, but with OAuth, you just hit the “log in with Facebook” or “log in with Google” button and go from there.
Adopting the fairly niche (and not particularly user-friendly) OpenID in 2008 was a technical decision that made sense at the time. The users of Stack Overflow were programmers, so expecting them to understand the technicalities of OpenID wasn’t too much of a big ask. It gave Stack Overflow benefits in that they didn’t have to build lots of functionality around passwords.
But as time passes, the world changes, and that means that these kinds of early decisions (and technical bets) don’t make sense forever.
In 2009, Stack Overflow launched Careers. A technical decision that was taken at this time was to launch it as a separate site to Stack Overflow. Based on a fork of the Stack Overflow Q&A codebase, it sat on a separate subdomain and shared a look and feel, but otherwise was pretty much completely separate. This was another decision that made good sense at the time. No need to clutter up the Q&A codebase with a load of stuff about jobs, and maybe as the Q&A network grew with the launch of other sites to cover topics outside of programming (such as Server Fault for system admins), those other sites could have separate job boards of their own too. On the other hand, if Careers failed to take off, it could be easily shut down without requiring a big clean-up job.
With Careers being a separate site, it needed its own login mechanism. But now OpenID presented a problem. Whereas the Q&A site had been set up for programmers, the Careers site needed to be easily accessible to employers, who might not be so technical. New audience, new requirements - and OpenID wasn’t going cut it. It needed to be as easy as possible for employers to log in, in the way they would be used to - using a username and password. Anything more complicated than that would risk putting some potential customers off, which would mean less money coming in.
The simplest way to build the ability to log in with a username and password, to fit in with the architectural principles, was to create a simple OpenID provider that employers could use, one which would only ever be supported for logging in to Stack Overflow Careers. Thus CareersAuth was born. A simple, behind-the-scenes OpenID provider, which could be consumed by Stack Overflow Careers. Employers logging in with a username and password would never know they were using it. And the login code on Careers could carry on not caring about usernames or passwords - it would treat CareersAuth the same way as any other external OpenID provider.
Later, in 2011, Stack Overflow Q&A finally began to support usernames and passwords itself, by becoming a fully fledged OpenID provider. This was a new implementation - rather than reuse or extend the Careers one, this one was created from scratch. That makes some sense - why risk breaking Careers logins? - but it now meant the company was maintaining two OpenID providers.
In 2016, with OpenID dying, this was clearly two too many.
A plan to fix it
So that’s how the technical debt came about. How did I fix it?
Slowly, carefully, and with planning.
Although this technical debt was slowing me down with the work I was doing to update the login pages, I didn’t try to fix it immediately. That would have been a lot of scope creep for that task. I finished the work with the technical debt still in place - I wasn’t about to try to “sneak in” a rewrite of the login back-end alongside this front-end change. But, I allowed myself enough autonomy over my work to spend a day or two doing research about the change I wanted to make, and write it up as an RFC.
An RFC is a “Request For Comments” document. Stack Overflow had a process for these - anybody could propose a change, write it up in an RFC document, and circulate it around the company to get feedback. There was a dedicated mailing list for this, where RFCs would be sent to other developers, support staff, management and marketing. (If your company doesn’t have an official RFC process, you can still do the same thing - just send around a document by email to as many relevant people as possible, and ask for feedback and comments on it.)
Here’s a lightly edited version of the RFC I sent around:
RFC: Operation Nuke CareersAuth
Problem
When users log in to Careers using an email address and password, that is handled by a separate app and database called CareersAuth. This is technical debt - it is overly complex for the simple functionality it provides. It also means that:
- Users cannot change their passwords while logged in, they have to use the “forgot password” functionality to get a password reset emailed to them.
- When users change their email address on Careers, this is not reflected in the separate CareersAuth database, which means they can’t get a password reset sent to their new email address.
CareersAuth is implemented as an OpenID provider. It pre-dates StackAuth, which is also an OpenID provider. It would be desirable for us not to maintain two OpenID providers, and it would also be desirable for users to be able to log in to Careers using the same email address and password they use to log in to Stack Overflow.
Background
At the time CareersAuth was implemented, StackAuth did not exist. The only way to log in to Careers was via a separate OpenID provider, but this adds complexity for users, as they need to use or set up an account on a third-party website to log in to ours. CareersAuth was created as an in-house OpenID provider so users could log in to Careers using a username and password. This is implemented using the standard ASP.NET SQL Membership Provider and DotNetOpenAuth to implement OpenID. This way, Careers can talk to CareersAuth just the same as if it were an external OpenID provider.
DotNetOpenAuth is apparently no longer maintained (though I can’t find a source for this) and the ASP.NET Membership provider is not great. Careers only needs to identify a user logging in with an email address and password, and it already has access to the CareersAuth database, so OpenID seems overkill - a user will never use their CareersAuth credentials to log in to any other website.
Proposed Solution
Stage 1: Nuke the CareersAuth app
The Careers app can handle all CareersAuth functionality by talking directly to the CareersAuth database.
There is no great magic to how the ASP.NET SQL Membership provider works, so this functionality is relatively easy to implement ourselves using Dapper.
Here is a link to a prototype: [link to a GitHub branch]
The feature flag BypassCareersAuth toggles whether Careers uses the CareersAuth app via OpenID, or whether it uses the new code in AuthService.
When we turn this feature flag on in production, the CareersAuth app can be switched off.
Stage 2: Nuke the CareersAuth database
Migrate the following CareersAuth tables to the main Careers database:
aspnet_Membershipaspnet_Usersopenid_aspnet_UsersPasswordResetRequest
The remaining tables in CareersAuth are not required by the BypassCareersAuth implementation.
There is also an aspnet_Membership_CreateUser stored procedure. We could either migrate this or just call the same SQL directly.
Future Stages
These need a bit more thought, so are not in scope for right now (but if you do have thoughts, please share them!)
- Fixing the data model. Currently we have email addresses in three places -
CareersAuth.aspnet_Membership.Email,CareersAuth.aspnet_Users.UsernameandCareers.Users.Email. When a user’s email address is changed in Careers, we do not update the CareersAuth data. This means we have to check additional usernames (CareersAuth usernames are just email addresses) in the login code, as the login username is still the old email address. It also means currently you can’t send a password reset to your new email address. Users can log in using their old or new email address. There’s also nothing to stop you changing your email address on Careers to one that has an existing CareersAuth account. Needs more thought about how to tidy this up. - Migrating to StackAuth. This seems desirable so people can use the same username+password on Careers as they do on SO. Needs more thought about how to handle this, especially what to do about accounts that already exist in StackAuth.
Feedback
I got some really useful feedback from this - lots of positive comments, but also a few things which helped me to refine and simplify the plan, and showed other benefits of doing this work:
“Is migration to StackAuth actually worth doing? StackAuth is kind of a gross hack, and it would put a lot of burden on Careers (and Core) to share it’s functionality.”
My big plan had been to eventually move everything in CareersAuth over to the “other” OpenID provider, giving a universal login across Stack Overflow and Careers. But I wasn’t familiar at all with the other OpenID provider we maintained internally - and comments like this helped me to reduce my ambitions somewhat, keeping things simple by reducing the scope of this work.
“Great! One less thing to worry about during failovers and no more ‘What the heck is CareersAuth again?’ So I anticipate you are making SREs happy.”
I hadn’t even thought about the benefits to SRE (Site Reliability Engineering), reducing complexity for them too.
“Looks good, very pragmatic approach, particularly using Dapper rather than that bloody horrible ASP.NET membership cruft… I’m not sure there’s really any advantage to moving the data into Careers if we’re considering a move to StackAuth? Seems like it’ll add additional complexity for little benefit (Careers can already read/write to CareersAuth). Also, wondering if there’s any security advantages to keeping it as a separate DB?”
Another comment that helped to keep things simple. I was talking about migrating the CareersAuth database into the main Careers one - but was there really any benefit to doing that? It turns out, no, and keeping it separate may even be better anyway.
“Part of deprecating CareersAuth also involves tearing down the website/app pools, TeamCity configs etc. I’m guessing we need to get SRE involved here; both to get rid of the dev/prod config and to make sure they’re aware of it in their failover plans.”
Up until this point, my plan would have involved Careers simply not using the CareersAuth app - but CareersAuth would still have sat there idle. This showed me that I needed to speak to some more people so we could actually get it properly decommissioned.
Implementation
A plan had come together, and we were agreed on a way forward - all without a single meeting. I created a further document with an actual implementation plan, showing who was doing what and when, and how we would test all of this, to ensure that we wouldn’t break everything.
My manager gave the OK for the work to go ahead, and a couple of weeks later, the old CareersAuth app was no more. We now had a shiny new login page, and a much simpler process behind the scenes.
There was still work to do - for example, that “change password” functionality actually needed implementing, but at least that sort of thing would now be much simpler.
Conclusion
Technical debt can exist for many reasons, but it’s often the result of a series of decisions which, while they made sense at the time, may no longer make sense due to changes in the business and the wider world. Stack Overflow started out as a Q&A site for programmers, took a bet on the world adopting a particular way of authenticating with websites, and needed to adapt when it expanded its audience to less technical people. Meanwhile the world decided on a different way of authenticating with websites, which left Stack Overflow Careers with a login architecture that didn’t work well any more.
Developers have the power to fix technical debt, but you can’t just dive in and start rewriting things. Instead, spend some time doing research, communicate with your fellow developers and the wider business, and come up with a plan. You may get more buy-in than you think, because there may be other benefits of fixing the technical debt that you haven’t realised. You also may get some legitimate push-back - maybe some of the work you’re proposing isn’t actually necessary. This can all be very useful information, and will help you invest the right amount of effort to get a good outcome for everybody.